

Learning Apache Spark Streaming API
Spark Streaming API
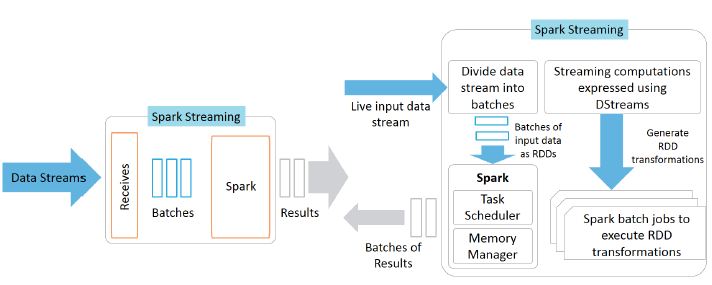
It is the core Spark API’s extension that allows high-throughput, scalable, and fault-tolerant stream processing of data streams that are live. There are many sources of ingesting data such as Flume, ZeroMQ, Twitter, Kinesis, and Kafka. It first takes live input data streams and then divides them into batches. After this, the Spark engine processes those streams and generates the final stream results in batches.

The fundamental stream unit is DStream which is basically a series of RDDs to process the real-time data.
Micro Batch
Micro batching is a core Spark technique that lets a task or process handle a stream as a sequence containing data chunks or small batches. In case of incoming streams, events can be packed into various small batches and then delivered for processing to a batch system.
Streaming Context
Streaming Context consumes a stream of data in Spark. It registers an Input DStream to produce a Receiver object. It is the main entry point for Spark functionality. Spark provides a number of default implementations of sources like Twitter, Akka Actor and ZeroMQ that are accessible from the context. StreamingContext object can be created from a SparkContext object. A SparkContext represents the connection to a Spark cluster and can be used to create RDDs, accumulators and broadcast variables on that cluster.
import org.apache.spark._
import org.apache.spark.streaming._
var ssc = new StreamingContext(sc,Seconds(1))
Can SparkContext and StreamingContext co-exist in the same program?
yes they can, first start spark session and then use its context to start any number of streaming context
val spark = SparkSession.builder().appName("someappname").
config("spark.sql.warehouse.dir",warehouseLocation).getOrCreate()
val ssc = new StreamingContext(spark.sparkContext, Seconds(1))
Prior to spark 2.0.0 sparkContext was used as a channel to access all spark functionality. The spark driver program uses spark context to connect to the cluster through a resource manager (YARN orMesos..). sparkConf is required to create the spark context object, which stores configuration parameter like appName (to identify your spark driver), application, number of core and memory size of executor running on worker node
In order to use APIs of SQL, HIVE, and Streaming, separate contexts need to be created like below:
val conf=newSparkConf()
val sc = new SparkContext(conf)
val hc = new hiveContext(sc)
val ssc = new streamingContext(sc)
SPARK 2.0.0 onwards SparkSession provides a single point of entry to interact with underlying Spark functionality and allows programming Spark with Dataframe and Dataset APIs. All the functionality available with sparkContext are also available in sparkSession. In order to use APIs of SQL, HIVE, and Streaming, no need to create separate contexts as sparkSession includes all the APIs. Once the SparkSession is instantiated, we can configure Spark’s run-time config properties
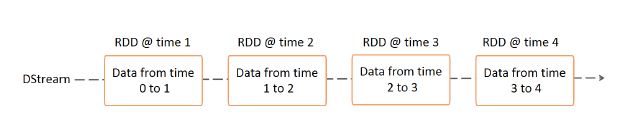
DStreams
Spark streaming provides a feature called discretized stream or DStream that is a high-level abstraction. It represents a continuous stream of data and is represented as an RDD sequence internally. They can be created by either applying high-level operations on other Dstreams or by using input data streams. These streams are available from sources like Flume, Kinesis, and Kafka. Also, internally, it is characterized by a series of RDDs that is continuous. All operations that you apply on a DStream get translated to operations that are applicable to the underlying RDDs.
Architecture of Spark Streaming: Discretized Streams
Instead of processing the streaming data one record at a time, Spark Streaming discretizes the streaming data into tiny, sub-second micro-batches. In other words, Spark Streaming’s Receivers accept data in parallel and buffer it in the memory of Spark’s workers nodes. Then the latency-optimized Spark engine runs short tasks (tens of milliseconds) to process the batches and output the results to other systems. Note that unlike the traditional continuous operator model, where the computation is statically allocated to a node, Spark tasks are assigned dynamically to the workers based on the locality of the data and available resources. This enables both better load balancing and faster fault recovery.
In addition, each batch of data is a Resilient Distributed Dataset (RDD), which is the basic abstraction of a fault-tolerant dataset in Spark. This allows the streaming data to be processed using any Spark code or library.
Input DStreams and Receivers
Input DStreams represent the input data stream that is received from sources of streaming. Except for file stream, each input Dstream is linked with a Receiver object. This object stores the data received from a source in the memory of Spark for processing. There are two topologies or categories of built-in streaming sources provided by Spark streaming:
basic sources - Basic sources are available in the StreamingContext API directly. A few examples are socket connections and file systems.
advanced sources - advanced sources include Twitter, Flume, Kafka, and Kinesis, and are available from extra utility classes. These sources need to be linked against extra dependencies.
*Note that you can create various input DStreams in case it is required to receive various data streams in parallel in the streaming application. Doing so will create various receivers to receive multiple data streams in parallel.
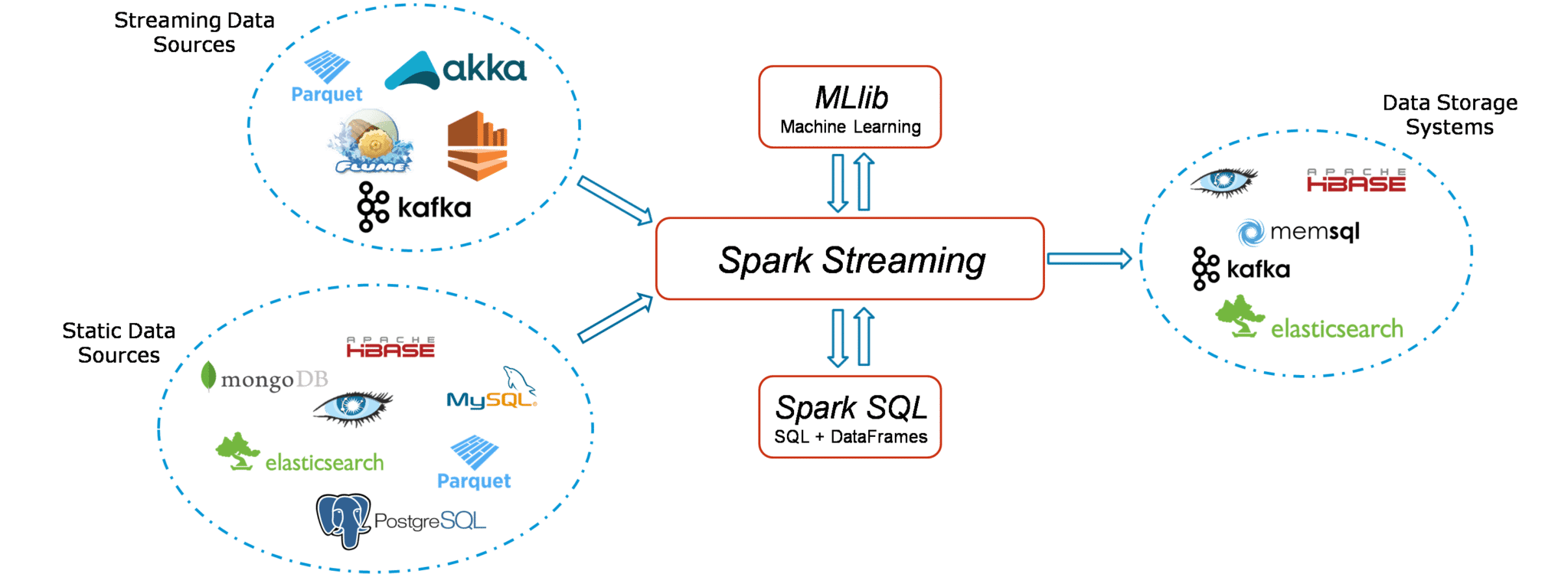
Spark Streaming Workflow
Spark Streaming workflow has four high-level stages:
- The first is to stream data from various sources. These sources can be streaming data sources like Akka, Kafka, Flume, AWS or Parquet for real-time streaming.
- The second type of sources includes HBase, MySQL, PostgreSQL, Elastic Search, Mongo DB and Cassandra for static/batch streaming.
- Once this happens, Spark can be used to perform Machine Learning on the data through its MLlib API. Further, Spark SQL is used to perform further operations on this data.
- Finally, the streaming output can be stored into various data storage systems like HBase, Cassandra, MemSQL, Kafka, Elastic Search, HDFS and local file system.
Running Streaming application
Spark worker or executor takes one of the cores that is allocated to the Spark streaming application. The reason is that it is a long-running task. Hence, you should remember that the application is required to be allocated sufficient cores for processing the received and running receivers. In case when a Spark Streaming program is run locally, you should not use “local[1]” or “local” as the main or master URL. If you do so, it would mean that one thread is used to run tasks locally. In case we use an input DStream on the basis of a receiver, then one thread would be used for running the receiver. This will not leave any thread to process the data received. Therefore, in such cases, you should every time use “local[k]” as the main or master URL. Here k is a number greater than the number of receivers to run.
Another important point is related to the logical extension to run on a cluster. The core number that is allocated to the application of Spark Streaming needs to be greater as compared to the receivers’ number. If that does not happen, the system will not be able to process the received data.
Built-in streaming sources: Basic sources.
For these sources, Spark streaming monitors the dataDirectory and processes all files that are created in it. The files in this directory must be in the same data format and must be created by moving or renaming them atomically. These files must not be altered once they are moved. The new data will not be read if the files are being appended continuously. File streams do not need allocating cores because they do not need running a receiver. Basic sources can be divided into two categories: streams that are based on custom actors - you can create DStreams with data streams that are received through Akka actors by using the given method. queue of RDDs as a stream - you can also create a DStream using the given method to test a Spark streaming application. Every RDD that is pushed into the queue is processed like a stream and treated like a data batch in the DStream.
Advanced Sources: Kafta, Flume, Kinesis, and Twitter
Pointers to start learning about Apach Spark Streaming:
- Spark Streaming Programming Guide
- Spark Streaming Tutorial – Sentiment Analysis Using Apache Spark
- Apache Spark Streaming Tutorial
- Do You Know all about Apache Spark Streaming? Read This.
- Diving into Apache Spark Streaming’s Execution Model
- Discretized Streams: Fault-Tolerant Streaming Computation at Scale
- Spark Streaming Window Operations- A Quick Guide
- Spark Streaming: Windowing